Generative AI dominates the conversation. Every conference keynote, every vendor pitch, every boardroom strategy session - it all seems to revolve around large language models, ChatGPT, and the promise of machines that can think and write like humans. But if you’re operating in regulated financial services, this fixation on generative AI is not just unhelpful. It’s actively dangerous.
The problem is not that generative AI is bad technology. It isn’t. It’s remarkable, and for certain tasks - drafting marketing copy, summarising internal documents, powering chatbots - it’s genuinely transformative. The problem is that the public conversation has collapsed “AI” into a single concept, when in reality it’s a broad family of fundamentally different approaches, each with radically different strengths, costs, and regulatory implications.
The tool you need to generate a picture of a unicorn duck is not the same tool you need to accurately extract data from a bank statement for a mortgage application. Confuse the two, and you’ll either burn money on over-engineering or, far worse, create compliance nightmares that your regulator will be very interested to hear about.
AI isn’t new - so why is everyone talking about it now?
Artificial intelligence has been used in financial services for decades. Rule-based expert systems were processing underwriting decisions in the 1980s. Machine learning models have powered fraud detection and credit scoring for years. None of this is novel. What changed is that large language models - built on billions of parameters and trained on vast swathes of the internet - removed the single biggest barrier to AI adoption: the need for specialist training. Previously, if you wanted a model that could do something useful, you needed to collect task-specific data, train or fine-tune a model from scratch, and employ a team of machine learning engineers to build and maintain it. That was expensive, slow, and inaccessible to most organisations.
LLMs changed the equation entirely. They arrive pre-trained, astonishingly versatile, and are usable of the box. The trade-off is that this versatility comes at enormous computational cost, and it comes without the precision, predictability, or explainability that regulated environments demand. That trade-off is the crux of the decision every financial services firm now faces.
What the FCA actually requires
Before reaching for any AI solution, it’s worth understanding what the Financial Conduct Authority expects of firms deploying automated decision-making. The FCA has been clear that it is not introducing AI-specific regulation - instead, it expects existing frameworks to be applied rigorously. The Consumer Duty, the Senior Managers and Certification Regime, and the Principles for Businesses all apply to AI just as they do to any other tool.
In practice, this means three things. First, explainability: if your AI declines a mortgage application, you must be able to explain why in terms that a consumer can understand. As the FCA has stated, there is “growing consensus around the idea that algorithmic decision-making needs to be 'explainable'”, and that when a product is denied to a consumer, “we need to be able to point to the reasons why”. Second, auditability: boards and senior managers must ensure that AI-driven decisions are transparent and auditable, and accountability under the SM&CR is, in the FCA’s words, “non-negotiable”. Third, fairness: AI must not embed or amplify bias, and firms must be able to evidence the fairness of their algorithms. The FCA has published research specifically examining bias risks in supervised machine learning and language models, and has made clear that if AI systems result in unfair outcomes for consumers, enforcement action may follow.
These are not aspirational principles. They are enforceable obligations. And they have a direct bearing on which type of AI you can credibly deploy in production.
Three questions that determine which AI you need
The choice of AI type should not begin with which technology is most fashionable. It should begin with the problem you are trying to solve, then work through the constraints that govern your operating environment. In practice, you can get to the right answer by asking three questions in order.
1. Will it be used to make a regulated decision?
If your AI’s output informs a lending decision, an affordability assessment, a compliance check, or anything else that falls under FCA oversight then you need every output to be explainable, auditable, and consistent. That rules out generative AI and LLMs for the task itself, unless you’re going to check every single datapoint, which rather defeats the point. Those models are opaque by design - they produce outputs through billions of ‘weights’ deciding connections that no human can meaningfully trace. Engineers call this the “black box” problem, and it is not a limitation that can be engineered around; it is a fundamental property of how these models work. If the answer to this question is no - say, you’re building an internal research tool or a customer-facing chatbot - then generative AI may well be the right choice, provided a human is reviewing the output before it reaches a customer or informs a decision.
2. Are you trying to recognise a pattern, and is any margin of error acceptable?
Some tasks genuinely benefit from machine learning: fraud detection, customer segmentation, sometimes even credit scoring. These models learn from historical data and can identify signals that rule-based systems would miss. The trade-off is that they carry real risks around bias - they can only be as fair as their training data - and they require ongoing monitoring and governance. The FCA has been explicit that firms deploying ML in consumer-facing applications must embed bias audits and fairness testing into their model governance. If a margin of error is acceptable and human oversight is built into the process, machine learning can be an excellent choice. But it requires a governance framework that many firms underestimate.
3. Does the task involve data available already from documents, emails, or web pages?
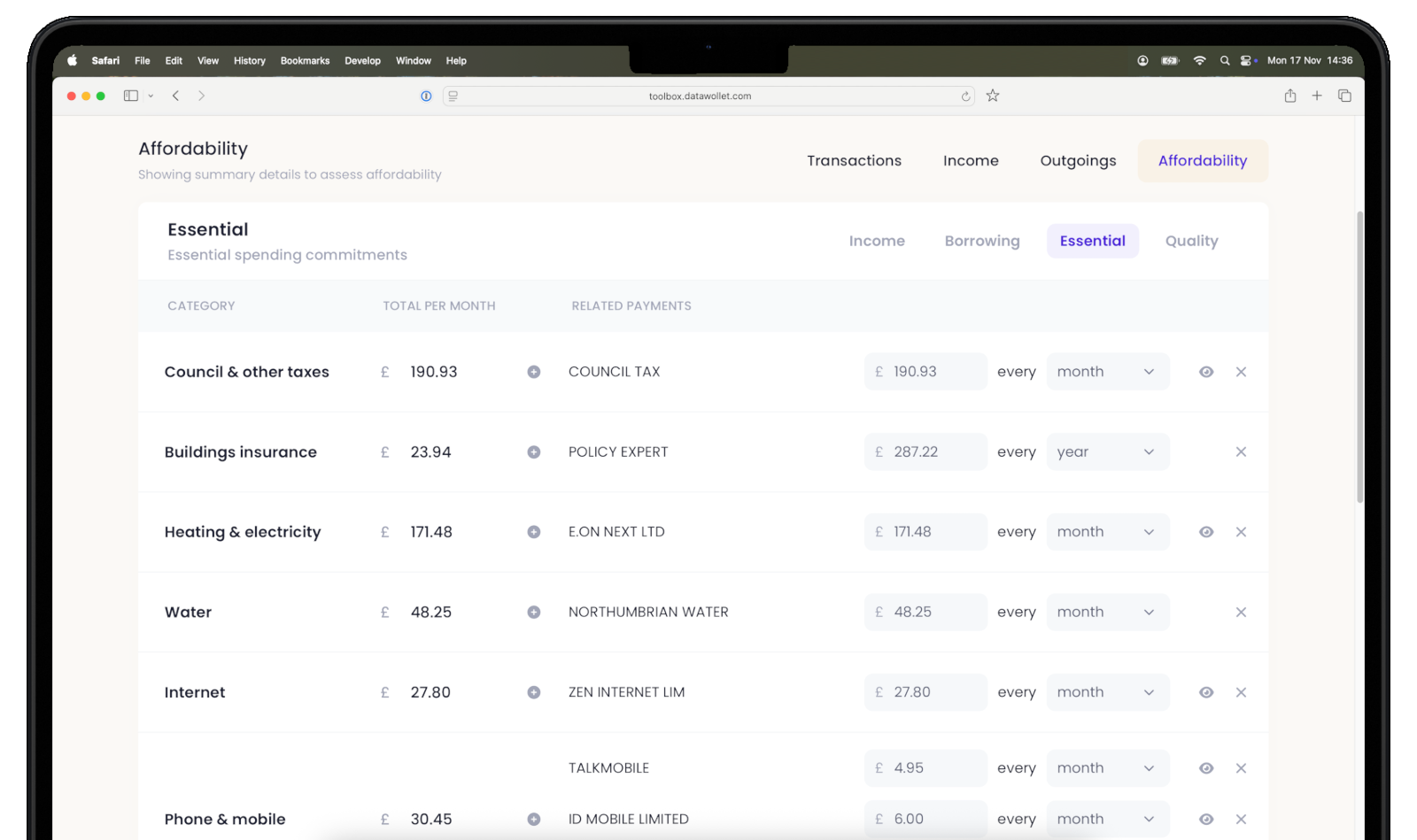
If you need to read bank statements, interpret payslips, or parse tax returns, then you need outputs that are identical every time the same document is processed - the same result, every time. An LLM will give you a different answer to the same question every time, because part of the process is random. What you want in this case though, is a system that extracts exactly what is on the page, no more and no less, and certainly no assumptions or guesses. That points to logic-based AI: rule-driven, fully traceable, and producing the same output for the same input without exception.
In short: if the task is regulated and requires consistency, use logic-based AI. If it requires pattern recognition with acceptable error margins, use machine learning with proper governance. If it needs creativity or natural language generation and a human will verify the output, generative AI has a role to play. The type of AI your compliance team would be happiest with is almost certainly not the one getting the most attention in the press.
The risks of choosing the wrong type
The consequences of selecting the wrong AI type for a regulated task are not hypothetical. During our own testing at DataWollet, we asked an LLM to extract financial data from bank statements. In one case, the model identified a single credit card payment of £850 and inferred that this was a regular monthly repayment. A reasonable-looking assumption - except it was wrong. It was a one-off payment; the other months showed minimal repayments, and combined with a hefty balance on the card it meant the debt was growing. Had this extraction been used in an affordability calculation, it could have resulted in approving a loan the applicant could not afford to repay. That is a Consumer Duty breach and a material credit risk, caused by a single wrong output from an LLM.
This illustrates the deeper problem with LLMs in regulated applications: they are designed to be helpful. They always want to give you an answer, and they will fill in gaps with plausible-sounding guesses rather than flagging uncertainty. If five out of six data points are accurate, the natural human response is to trust the sixth. This creates what might be called “false confidence” - a situation where the presence of AI actually makes verification harder, not easier, because the output looks so convincing.
Beyond hallucination, there are further risks to consider. LLMs are non-deterministic: the same input can produce different outputs on each run, which makes them unsuitable for any process that requires consistency. They carry data security risks, since many cloud-based LLM providers may use inputs to improve their models - meaning your customers’ financial data could end up training a third-party system. And at scale, the cost of running every document through a generative model can be orders of magnitude higher than the alternatives when you try to squeeze as much accuracy as possible.
A logic-based alternative
DataWollet was built on a straightforward principle: for regulated financial services, the questionable outputs from machine learning and LLMs should be kept well away from the data you use to make a decision. By using logic-based AI for document extraction, we eliminate the categories of risk that make generative AI unsuitable for these tasks.
Our system extracts exactly what is on the page. It cannot hallucinate, because it does not generate - it reads. It produces identical results every time the same document is processed. Every extraction is fully traceable and auditable, meaning it can be explained to a regulator, a compliance officer, or a consumer. It uses approximately 0.8% of the compute required to process the same document through a generative model, making it viable at the kind of scale that mortgage lenders and financial platforms actually operate at.
In the context of open finance - where a complete picture of a consumer’s financial life requires data from current accounts, credit cards, pensions, mortgages, investments, and more - robust document extraction is essential. API coverage is expanding but remains incomplete, and many consumers still prefer to share financial data through documents rather than direct account connections. DataWollet provides a single gateway that supports both, giving consumers genuine choice and control over how their data is shared, without the complexity and trust barriers that have held back adoption.
The measurable outcomes speak to the approach: 100% typical extraction accuracy, a 26% lift in conversion due to reduced documentation friction, and over 30 minutes saved per loan application. These are not theoretical projections - they reflect what happens when you match the right type of AI to the right problem.
The right AI depends on the problem
The AI revolution in financial services is real, and the firms that embrace it thoughtfully will have a genuine competitive advantage. But “thoughtfully” is the operative word. It means starting with the problem, not the technology. It means understanding what your regulator requires before you evaluate vendors. And it means recognising that for most regulated tasks - the ones involving real consumers, real money, and real compliance obligations - the right AI is probably the one your compliance team would actually approve.
To find out how DataWollet’s logic-based approach can support your lending or open finance use case, get in touch at luke@datawollet.com.